Building the next generation of document Q&A with Casey
Published:
January 16, 2026

Document-intensive workflows demand speed and accuracy. This article examines how Casey’s document Q&A system evolved from traditional retrieval-based methods to a full-context, streaming architecture that delivers fast, consistent, and fully traceable responses for clinical reviewers.
The challenge: Speed meets accuracy in document review
In prior authorization workflows, reviewers are often given hundreds of pages of medical records and asked to answer precise questions—such as "Is this supported?" Where is it documented? Can I trust this answer? Every second spent searching is time not spent making decisions.
Prior authorization review demands more than fast answers. It requires answers that are correct, consistent, and verifiable against source documents. Traditional retrieval-augmented generation (RAG) systems struggle in this environment. By breaking documents into chunks and retrieving fragments for each question, they introduce several compounding limitations:
- Context fragmentation: Important details may be split across chunks, increasing the risk of missed nuance
- Retrieval latency: Every question requires a search step before generating an answer begins
- Inconsistent grounding: Different questions retrieve different chunks, causing inconsistent responses
- Conversation coherence: Multi-turn conversations struggle when different chunks are retrieved
In workflows where reviewers need immediate, trustworthy answers they can defend, these architectural constraints create friction—not just for speed, but for confidence.
A new approach: Full-context streaming with intelligent caching
We redesigned Casey around a simple principle: prepare once, answer many times. Instead of retrieving fragments for each question, we load complete case content once and cache it for reuse. This shift—from retrieval on every query to full-context streaming—became the foundation for everything that followed.
How the system works
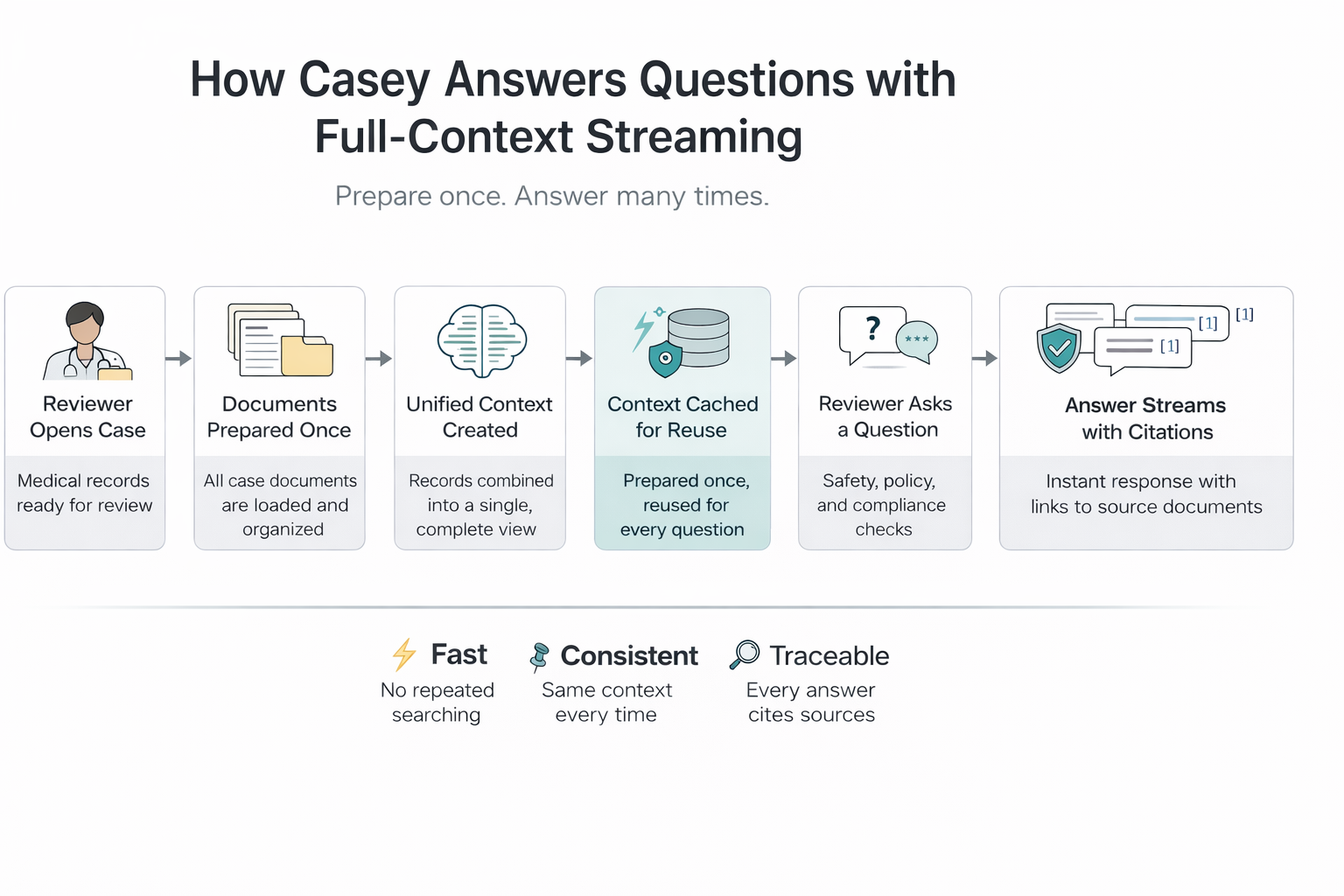
When a reviewer opens a case and engages with Casey, the system performs a one-time preparation step:
- Fetches all document data from cloud storage
- Builds a unified context with structured formatting
- Caches this context for reuse across sessions
- Validates each question against safety guardrails
- Streams responses in real-time using cached context
- Generates inline citations linking facts to source documents
Because the context is already prepared and cached, Casey can respond immediately without redundant retrieval or preprocessing.
This architectural shift delivers several key benefits:
- Speed: Responses stream immediately by eliminating redundant processing
- Consistency: Every answer draws from the same complete context
- Transparency: Citations link claims to specific document locations
For clinical reviewers, this means faster decisions, higher confidence, and fewer context switches.
The technical foundation
Intelligent caching strategy
Caching is the backbone of full-context streaming, and it operates at multiple layers:
- Document-level caching: When a document is first accessed, we fetch, parse, and normalize its content, including coordinate metadata. This cache is shared across sessions and automatically invalidates when documents change.
- Model-level prompt caching: We leverage the LLM provider's native prompt caching for system instructions and document context. On subsequent questions, only conversation history and the new question are sent; the model reuses cached context, reducing latency and token costs.
- Text normalization: We normalize line endings and whitespace to ensure consistent cache keys, preventing cache misses caused by formatting differences.
Real-time streaming
We stream tokens as they're generated. Users see answers appear word by word, creating a responsive experience that allows them to start reading immediately. We monitor time-to-first-token and streaming performance for every interaction to ensure responsiveness remains consistent at scale.
Built-in guardrails
Before any question is processed, we validate user input against multiple safety policies:
- Content filters for inappropriate requests
- Topic restrictions (block request) based on categories such as:
- Medical decision making - “Does this request meet the medical guidelines?”
- Indirect decision solicitation - “What parts of the clinical notes would be most relevant for determining medical necessity?”
- Task executions - “Change the status to Pending Missing Information”
- Custom word filters for organization-specific policies
- Sensitive information detection (e.g., PHI)
If any question is blocked, the user receives a clear explanation, and we record which policy triggered the decision. Guardrails are designed to be visible, predictable, and auditable—not silent features.
Inline citations by design
Citations are not an afterthought—they’re built directly into the generation process. As the model responds, it inserts citation markers that reference specific locations in the cached context. After streaming completes, we:
- Parse citation markers from the response
- Look up each reference in the document metadata
- Extract coordinates for highlighting
- Return structured citation objects with document name, page, and locations
This approach provides fast, accurate source attribution for traceability and helps build user confidence.
Handling large document sets
Most cases fit within the standard 200k token limit. For the small percentage (~5%) that exceed this, we automatically detect overflow and enable extended context (up to 1M tokens) at 2x cost, ensuring all documents remain accessible.
From the reviewer’s perspective, nothing changes. All documents remain accessible, and conversations continue seamlessly.
Measuring what matters
We instrument every interaction to ensure the system remains fast, grounded, and cost-effective:
- Performance: Time to first token, streaming duration, guardrail latency, cache build time
- Efficiency: Cache hit/miss rates, cache creation vs. read tokens
- Quality: Citation count, guardrail intervention rate, streaming interruption rate, hallucination rate, and live feedback
- Cost tracking: Input tokens (cached vs. uncached) and output tokens per question
Lessons learned
- Context isn't the bottleneck: Modern LLMs handle substantial context. The challenge is managing it efficiently through caching and normalization.
- Streaming transforms UX: It creates a perception of speed, allowing users to start reading while the model generates.
- Citations require first-class design: Building citations into the prompt ensures consistency.
- Guardrails need visibility: Clear feedback helps users understand system boundaries.
- Cache invalidation is hard: It requires careful document version tracking.
- Overflow handling matters: Automatic detection and extended context enable seamless handling of large document sets.
Looking ahead
Full-context streaming opens several paths forward. We're exploring:
- Continuous learning: Incorporating user feedback to improve quality
- Multi-modal support: Extending beyond text to handle charts, images, and structured data
- Proactive insights: Surfacing relevant information automatically
Closing thoughts
AI is most effective when it augments human judgment, not replaces it. AI augments human judgment by giving reviewers faster access to verified information. The shift from retrieval-based to full-context streaming recognizes that speed and accuracy aren't trade-offs—they're requirements.
Real-world AI systems succeed through thoughtful design that respects user workflows. That means building systems that are:
- Fast: Immediate streaming responses
- Accurate: Every claim traceable to sources
- Reliable: Guardrails prevent inappropriate responses
- Cost-effective: Prompt caching reduces token costs
Available For Download
Written by
J.D.
Martindale
J.D. has 10 years of experience creating novel AI/ML features and products in the health care space after obtaining his PhD in Applied Mathematics. He has worked across a broad spectrum of health care, from electronic health record vendors, to contract research organizations, to health insurance payers, before joining Cohere Health in April 2024 as Director of Machine Learning. His team's current focus is building end user-facing applications to streamline operations across our Intake and Review products using natural language processing and bleeding-edge generative AI techniques.
Stay ahead with expert insights on transforming utilization management and payment integrity—delivered straight to your inbox.

